セカンドブレインとは?
「セカンドブレイン」の概念は、パーソナルナレッジマネジメント(PKM)コミュニティから生まれました。アイデアは、生物学的な記憶から外部システムに情報をオフロードすることです。すべてを覚えようとする代わりに、必要な時に検索・取得できるノート、参考資料、アイデアの構造化されたリポジトリを作成します。
ほとんどのセカンドブレインの議論はメモアプリに焦点を当てています:Notion、Obsidian、Roam Research、Logseq。これらは重要です。しかし、全体像の一部しかカバーしていません。セカンドブレインには、今まさにブラウザタブに存在する散らかった進行中の情報を処理する方法も必要です。
このように考えてみてください:Notion はあなたの長期記憶です。ブラウザタブはワーキングメモリです。そして生物学的なワーキングメモリと同様に、ブラウザタブは揮発性です。閉じたり、クラッシュしたり、混乱に我慢できなくなったりすると消えます。完全なセカンドブレインシステムは両方に対処する必要があります。
ブラウザベースのセカンドブレインの3つの層
ブラウザを中心に構築された実用的なセカンドブレインには3つの異なる層があり、それぞれ異なるツールが担当します:
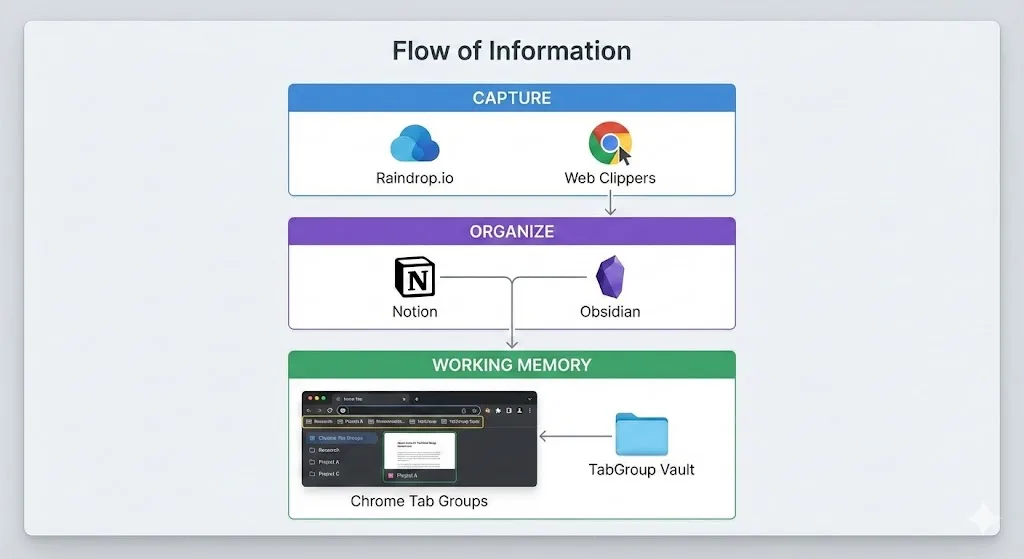
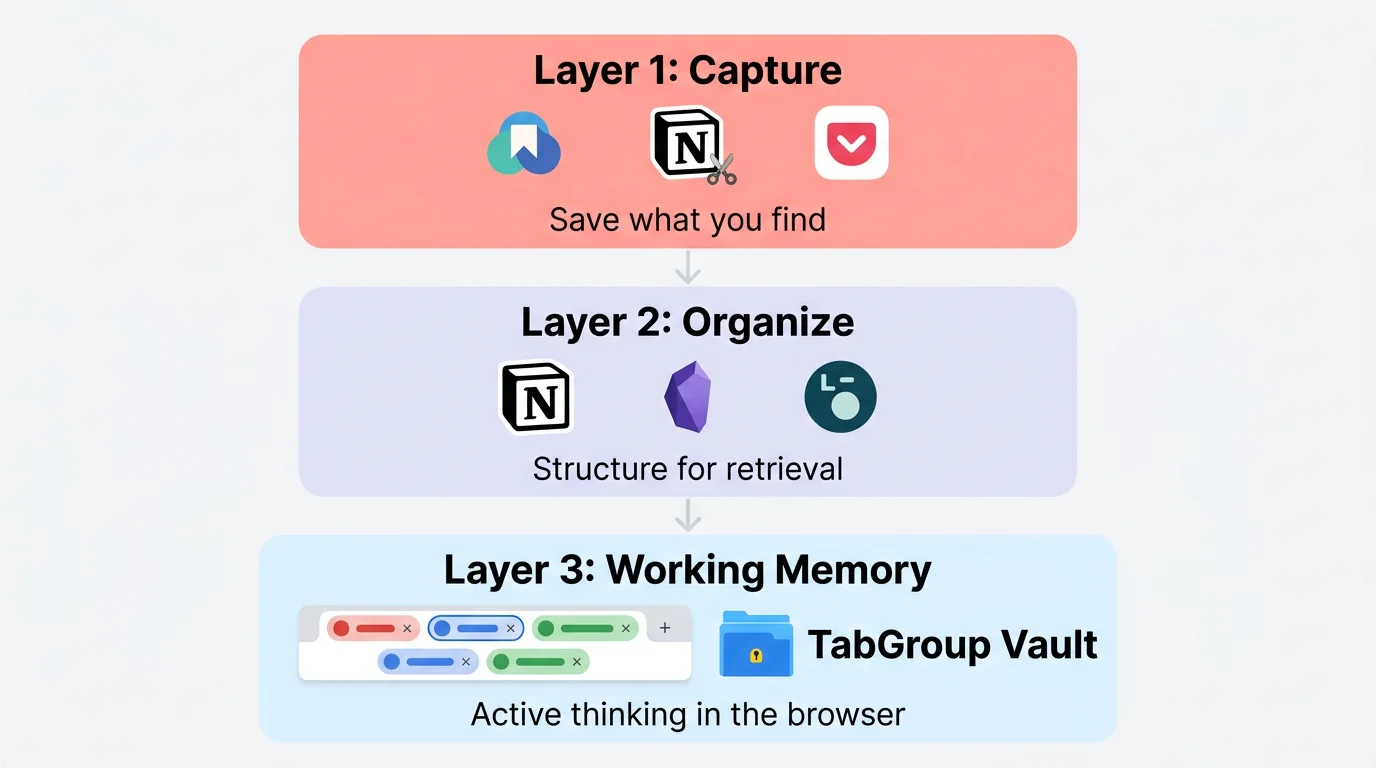
レイヤー1:キャプチャ -- 見つけたものを保存する
キャプチャ層は、ウェブから情報を取得して失われる前にシステムに入れることです。後で読みたい記事、必要になるかもしれない参考資料、閲覧中に目に留まったものが含まれます。
この層のツールは高速で摩擦がない必要があります。保存に2クリック以上かかると、一貫して行うことができなくなります。
- Raindrop.io:ウェブページを保存、タグ付け、コレクションに整理できるモダンなブックマークツール。Chrome のブックマークとは異なり、Raindrop.io はページのキャッシュコピーを保存し、全文検索をサポートし、コレクションを閲覧しやすいビジュアルインターフェースを持ちます。Chrome 拡張機能でワンクリック保存ボタンが追加されます。
- Notion Web Clipper:ウェブページを Notion ワークスペースに直接保存します。Notion がすでにプライマリのメモツールなら、クリップしたコンテンツがメモと一緒に保存されるので便利です。
- Pocket:専用の「あとで読む」サービス。クリーンな閲覧インターフェース、オフラインアクセス、タグ付けが特徴。気を散らさずに読みたい長文記事に最適です。
レイヤー2:整理 -- 検索用に構造化する
生のキャプチャは、必要な時に見つけられなければ無駄です。整理層では、構造を追加し、アイデア間のつながりを作り、検索可能なナレッジベースを構築します。
- Notion:構造化されたナレッジベースで最も人気のある選択肢。データベース、リンクされたページ、テンプレート、強力な検索により、プロジェクトノート、会議記録、参考資料ライブラリの整理に最適です。ブロックベースのエディタは単純なリストから複雑なリレーショナルデータベースまで何でも扱えます。
- Obsidian:プレーンな Markdown ファイルを使用するローカルファーストのメモアプリ。双方向リンクでノートをつなぎ、ナレッジグラフを可視化する機能が強みです。自分のデータを所有し、アイデア間のつながりを探求したい人に好まれます。
- Logseq:日常のジャーナリングとリンクされたナレッジを組み合わせたアウトラインベースのツール。箇条書きで考え、自動的な日次構造が欲しい人に向いています。
レイヤー3:ワーキングメモリ -- ブラウザでの能動的な思考
これはほとんどのセカンドブレインシステムが無視する層です。何かに積極的に取り組んでいるとき(リサーチ、比較、執筆、分析)、ブラウザタブは現在のワーキングセットを表します。これらはブックマークではありません。メモでもありません。今まさに考えるために使っている、ライブで進行中の素材です。
この層のツールは状態を保持し、コンテキストスイッチングをサポートする必要があります:
- Chrome タブグループ:トピックやプロジェクトごとにアクティブなタブを視覚的に整理。色分け、折りたたみ可能、Chrome に組み込み。
- TabGroup Vault:タブグループの状態をスナップショットとして保存。これがワーキングメモリを永続化するものです。現在の作業コンテキストを保存し、閉じて、別のことをして、後で復元できます。
TabGroup Vault
セカンドブレインのワーキングメモリ層。ワンクリックで Chrome タブグループを保存・復元。無料:10スナップショット。Pro($39 買い切り):無制限スナップショット、一括復元、Google Drive バックアップ、5つの Chrome プロファイル、ダークテーマ。
3つの層がどう連携するか
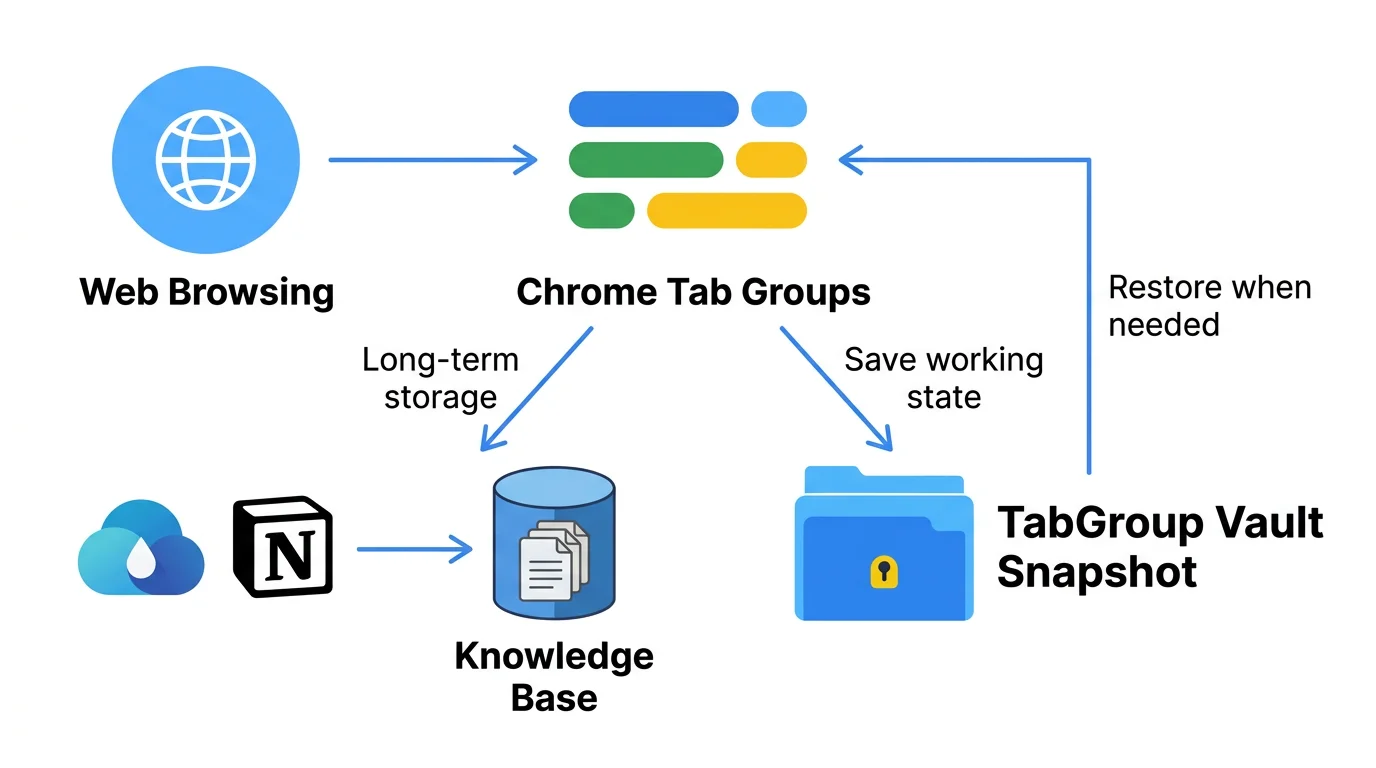
ブラウザベースのセカンドブレインの真の力は、3つの層がパイプラインとして機能する時に現れます:
- 閲覧して発見する。トピックを探索するにつれてタブが蓄積されます。
- 保存する価値のあるものをキャプチャする。長期保存に値するものは Raindrop.io や Notion のウェブクリッパーで保存します。
- ナレッジベースで整理する。専用のレビューセッションで、キャプチャしたものを処理:メモを追加し、タグ付けし、Notion や Obsidian の関連プロジェクトにリンクします。
- 作業状態を保存する。タスクを切り替える前に、TabGroup Vault でタブグループのスナップショットを保存します。これにより、まだキャプチャや整理されていないライブコンテキストが保持されます。
- 復元して続ける。トピックに戻ったら、スナップショットを復元して中断した場所から再開します。すでに処理したタブは閉じ、新しいタブを追加できます。
スナップショットは「生のブラウジング」と「整理されたナレッジ」の間に位置します。発見から保存への移行中に情報が落ちないようにする橋です。
システムの構築:実践的なセットアップ
30分で実装できる具体的なセットアップは次のとおりです:
| レイヤー | ツール | Chrome 拡張機能 | 目的 |
|---|---|---|---|
| キャプチャ | Raindrop.io | Raindrop.io 拡張機能 | タグ付きでウェブページをワンクリック保存 |
| 整理 | Notion または Obsidian | Notion Web Clipper(または Obsidian Web Clipper) | メモとリンク付きの長期ナレッジベース |
| ワーキングメモリ | Chrome タブグループ + TabGroup Vault | TabGroup Vault | アクティブなリサーチコンテキストの保存と復元 |
ステップ1:キャプチャツールをセットアップする
Raindrop.io(またはお好みのブックマークツール)をインストールし、主な関心分野や担当領域に対応する5〜10個のコレクションを作成します。構造はシンプルに保ちましょう。コレクションは後からいつでも追加できます。目標は、保存したいものに対して明確な場所を用意することです。
ステップ2:ナレッジベースをセットアップする
Notion を使う場合、トピック、ソースURL、キャプチャ日、ステータス(未処理、読書中、処理済み)のプロパティを持つ「ナレッジベース」データベースを作成します。Web Clipper 拡張機能をインストールします。Obsidian を使う場合、「Web Captures」フォルダを設定して Obsidian Web Clipper 拡張機能をインストールします。
ステップ3:ワーキングメモリをセットアップする
最もアクティブな2〜3個のプロジェクトまたはフォーカスエリア用の Chrome タブグループを作成します。TabGroup Vault をインストールして最初のスナップショットを保存します。これがベースラインの作業状態です。
ステップ4:処理のリズムを確立する
週に1回(キャプチャが多い場合は1日1回)、Raindrop.io の保存とタブグループのスナップショットをレビューします。未読のキャプチャをナレッジベースに処理します。他の場所にキャプチャ済みのタブを閉じ、新しいスナップショットを保存してタブグループをクリーンアップします。
ワーキングメモリのギャップ
ほとんどの PKM 愛好者は長期ストレージ層(Notion データベース、Obsidian グラフ、ツェッテルカステン方式)に執着し、ワーキングメモリ層を無視します。これが一般的なフラストレーションを生みます:美しく整理されたナレッジベースがあるのに、日常のブラウザ体験はまだ混沌としている。
その理由は、ナレッジワークは Notion の中で行われないからです。ブラウザの中で行われます。記事はブラウザで読みます。情報源はブラウザで比較します。ドキュメントはブラウザで調べます。能動的な思考が行われるのはブラウザです。Notion は結果が保存される場所です。
TabGroup Vault はブラウザのアクティブな状態をメモと同じくらい永続的で管理しやすくすることで、このギャップを埋めます。スナップショットはブックマークでもメモでもありません。それは保存された作業コンテキストです:開いていたタブの正確なセット、整理した方法のまま、そのコンテキストが再び必要になった時に復元する準備ができています。
異なる役割向けのセカンドブレインワークフロー
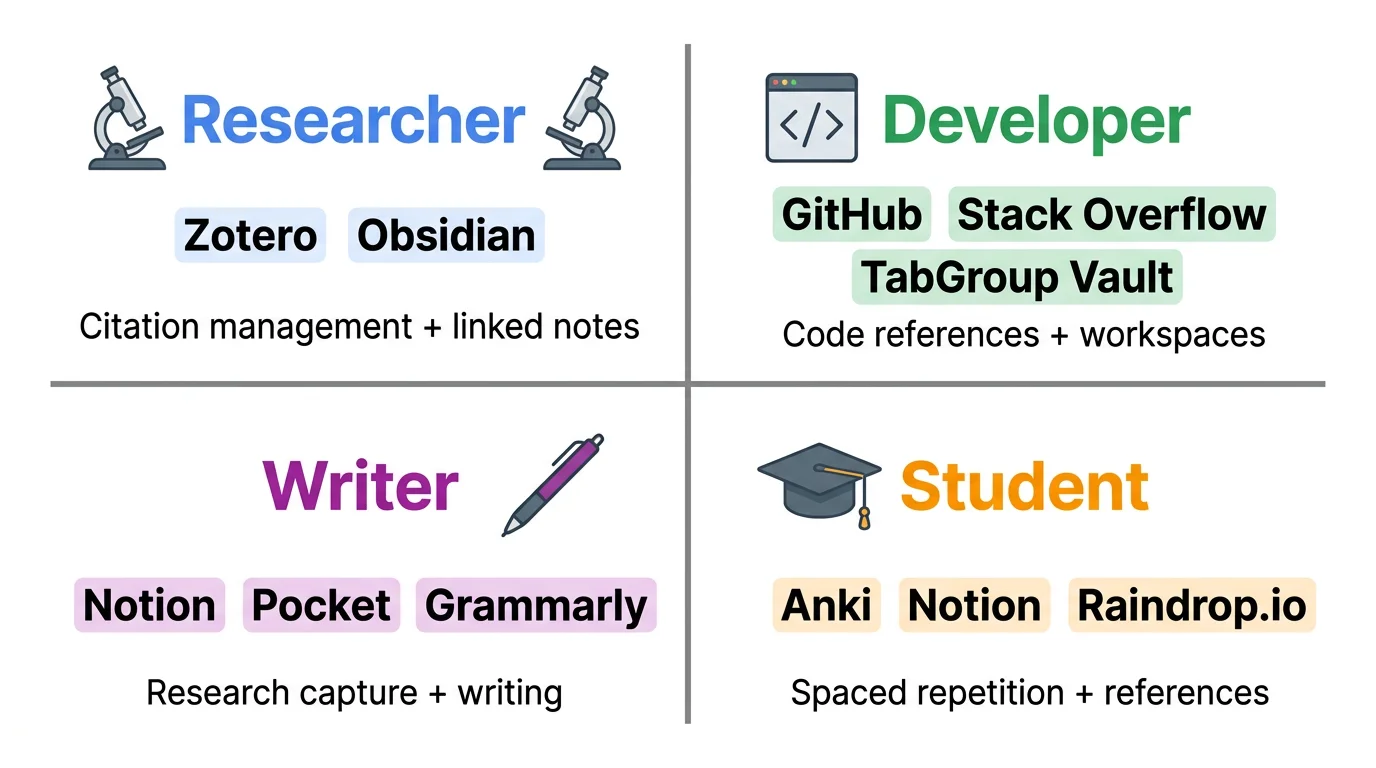
3層システムは異なる役割やワークフローに適応します:
- 研究者:キャプチャと整理の層が重い。研究テーマごとのタブグループ、文献レビューセッション用のスナップショット。論文、トピック、研究課題で構造化されたナレッジベース。詳細は学術研究ツールガイドをご覧ください。
- 開発者:軽量なキャプチャ、重いワーキングメモリ。プロジェクトごとのタブグループ、コードベース間のコンテキストスイッチング用スナップショット。コードスニペット、アーキテクチャ決定、学習メモ用のナレッジベース。開発者向け Chrome をご覧ください。
- ライターとコンテンツクリエイター:3層すべてでバランス。リサーチとインスピレーション用のキャプチャ。トピックアウトラインと参考資料用のナレッジベース。アクティブな執筆プロジェクト用のタブグループスナップショット。
- 学生:コースの読書用のキャプチャ。学習ノート用のナレッジベース。コースや課題ごとのタブグループスナップショット。学生向け生産性ツールガイドをご覧ください。
よくある落とし穴
セカンドブレインの構築自体が生産性のわなになる可能性があるので注意が必要です:
- システムの過剰設計。ナレッジベースの整理に使うよりも多くの時間を費やしているなら、シンプルにしましょう。タグ付きのフラットリストは、複雑な階層よりも実用的なことが多いです。
- すべてをキャプチャする。すべてが保存に値するわけではありません。6ヶ月後に検索しないものはキャプチャしないでください。タブとして生きて、閉じた時に消えるままにしましょう。
- ワーキングメモリ層を無視する。能動的なコンテキスト管理のないセカンドブレインは、閲覧室のない図書館のようなものです。資料を広げて作業する場所が必要であり、ただ保管するだけでは不十分です。
- ツールの乗り換え。各層で1つのツールを選び、少なくとも3ヶ月はコミットしましょう。毎週ツールを切り替えると、どのシステムにも有用になるほどのコンテンツが蓄積されません。
10分間の週次レビュー
毎週10分をセカンドブレインに費やしましょう:古いタブを閉じ、更新されたスナップショットを保存し、Raindrop.io や Notion の未読キャプチャを処理します。これによりシステムの陳腐化を防ぎ、ワーキングメモリを最新に保てます。
小さく始める
初日から3層すべてが必要なわけではありません。まずワーキングメモリ層だけから始めましょう:Chrome タブグループと TabGroup Vault。作業コンテキストの保存と復元に慣れましょう。それが習慣になったら、キャプチャツールを追加します。整理が必要なほどのキャプチャが集まったら、ナレッジベースを追加します。
セカンドブレインはニーズとともに成長するシステムであり、一度にすべてをインストールするシステムではありません。ブラウザはすでに時間を過ごしている場所です。それをパーソナルナレッジシステムのアクティブ層として機能させることが、最もレバレッジの高い出発点です。